
表形式のPDFをCSVへ変換したいと考えたことありませんか?
Pythonを利用してPDFをCSVへ変換してみました

ライブラリのインストール
tabula インストール
次のコマンドを実行
※Anaconda prompt
|
1 |
pip install tabula-py |
サンプルソース
厚生労働書の新型コロナウイルス陽性者数(チャーター便帰国者を除く)とPCR検査実施人数(都道府県別)
を利用しています
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import tabula #PDFファイルパス pdfPath = 'https://www.mhlw.go.jp/content/10906000/000618483.pdf' #PDFの読み込み dfs = tabula.read_pdf(pdfPath, stream=True,pages="all", encoding='shift_jis') #読み込んだPDFを確認 print(dfs[0]) #CSVへ出力 for df in dfs: df.to_csv("result.csv", index=None) |
実行結果
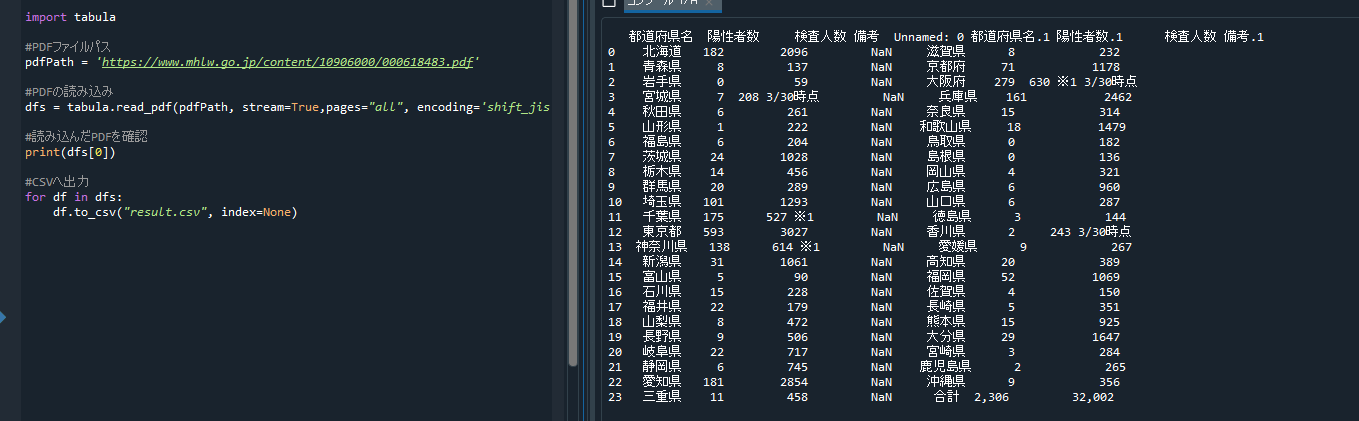
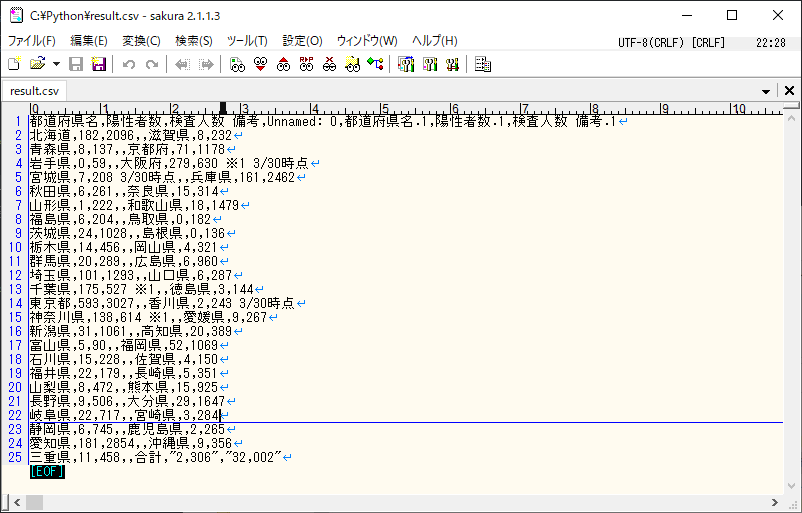
完ぺきではありませんが
PDFからCSVへ変換ができました
もう少し精度があがればいいですね
まとめ
本サイトはわかりやすさを重視
画像多めサンプルソースの公開を意識して作成しています
皆様の問題解決にお力添えできれば幸いです


コメント