

インストール
準備するものは3つ
- Java・・・OCRの利用にJava必須
- PyOCR・・・OCRを利用可能にするために必要なモジュール
- Tesseract-OCR・・・オープンソースのOCRエンジン
『OCR』とは
画像ファイルの文字をテキストとして読み込む技術です
Javaのインストール
Windows版Javaのダウンロード オフライン・インストール
環境に合わせてインストーラーをダウンロードして下さい
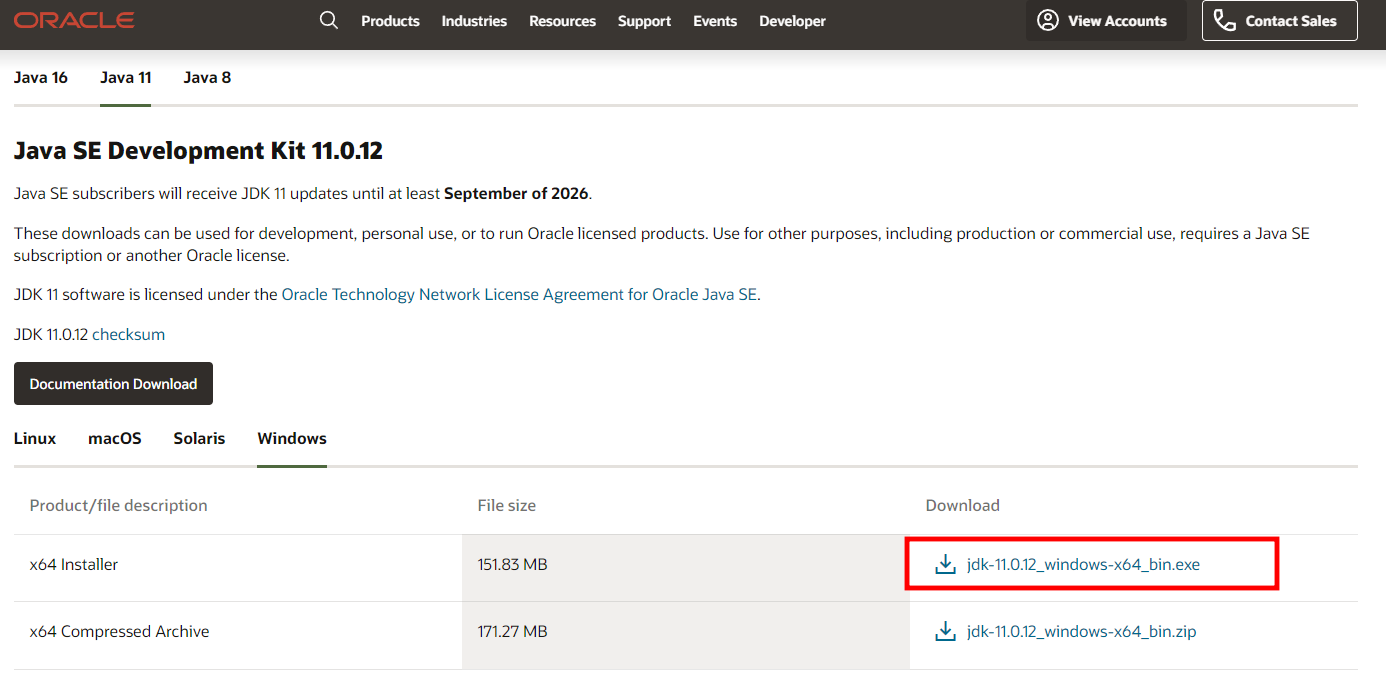
exeを実行します

インストール成功
Java環境変数の設定
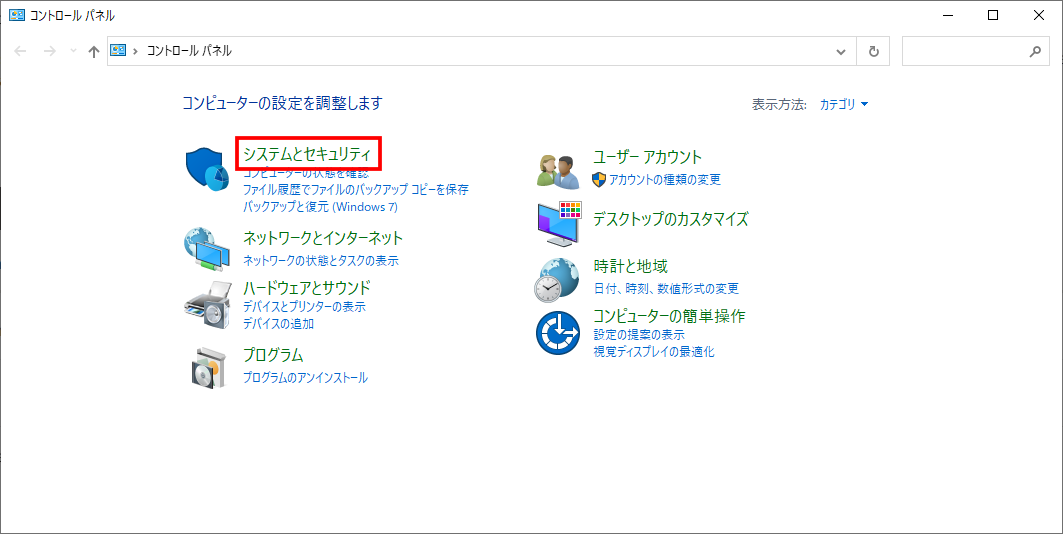
「コントロールパネル」を開く
「システムとセキュリティ」をクリック
「システム」をクリック
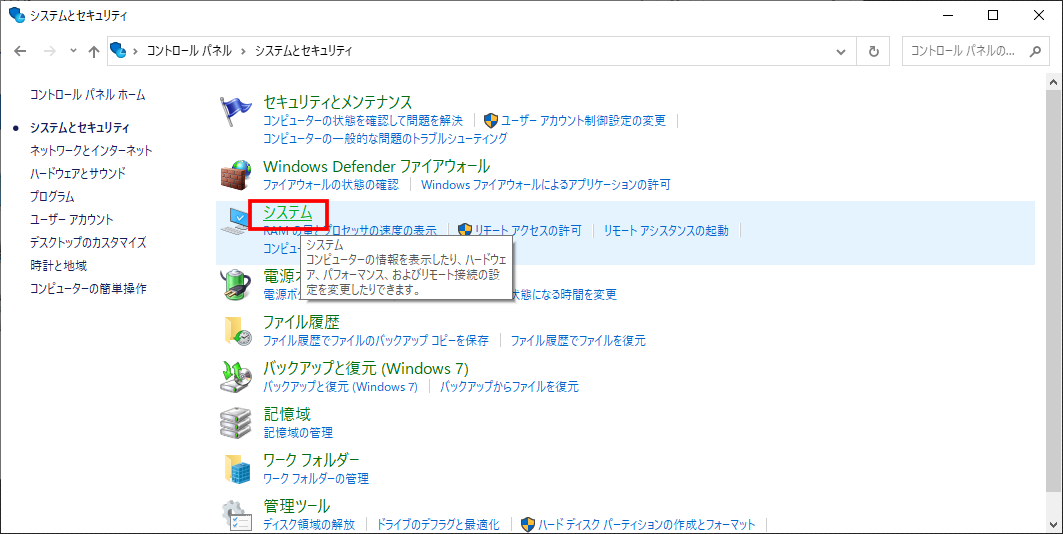
「システムの詳細設定」をクリック
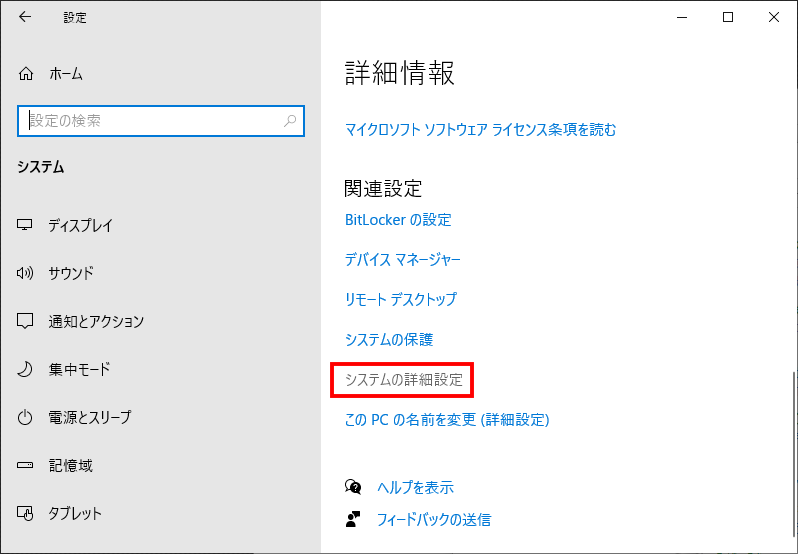
「環境変数」をクリック
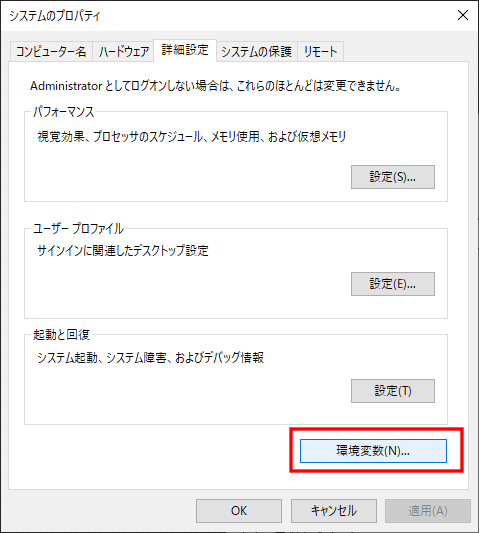
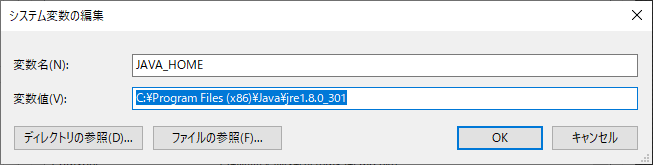
JAVA_HOMEを作成
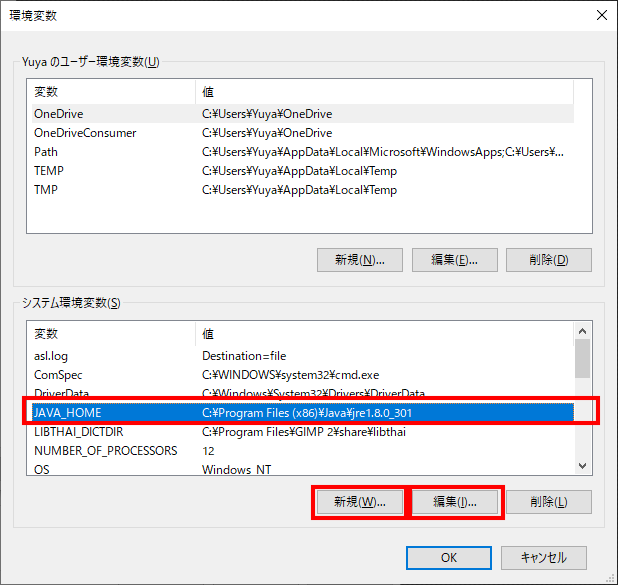
変数名:JAVA_HOME
変数値:C:\Program Files (x86)\Java\jre1.8.0_301
Java環境変数の設定確認
コマンドプロンプトにて次のコマンドを実行
|
1 |
set JAVA_HOME |
![]()
環境変数が設定できています
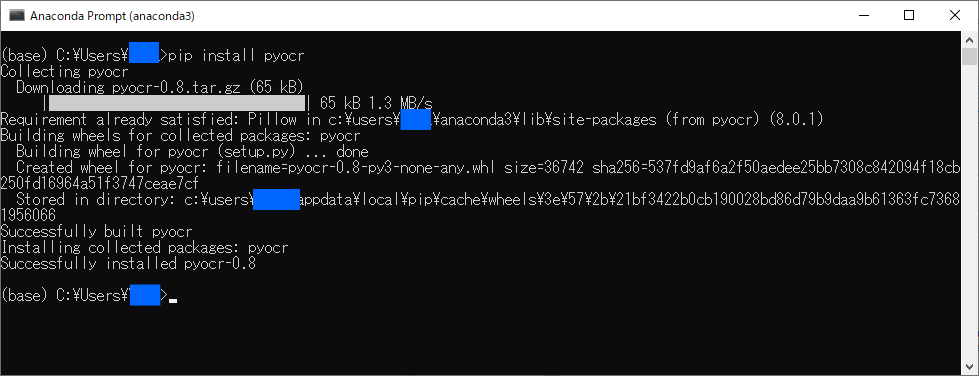
pyocrインストール
|
1 |
pip install pyocr |
Tesseract-OCRインストール
|
1 |
pip install tesseract |
こちらからインストーラーをダウンロード
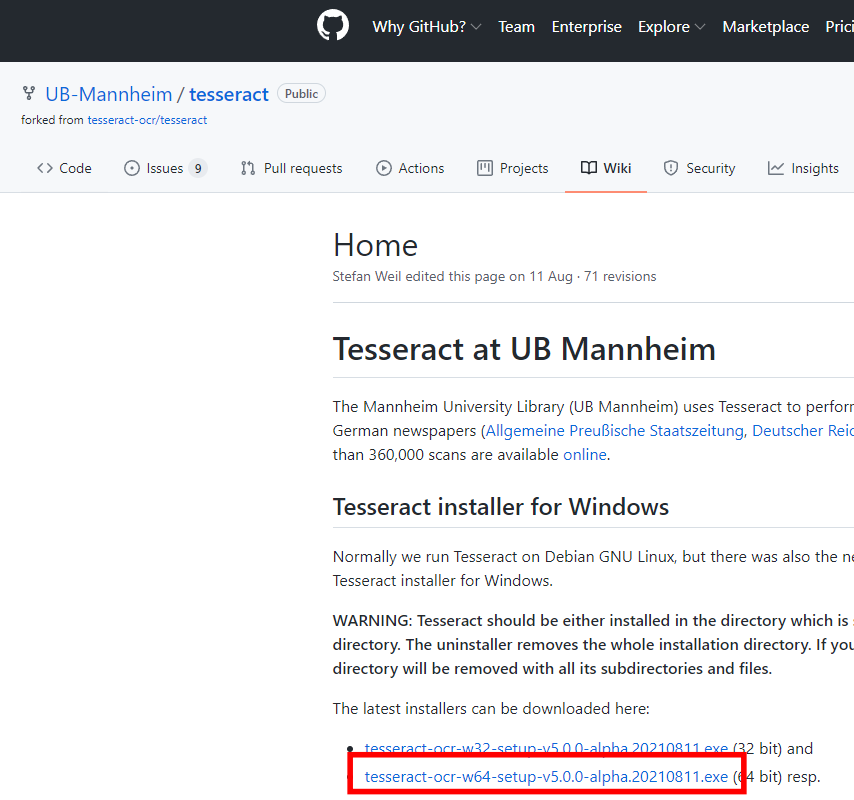
インストーラーを実行
「Next」クリック
「I Agree」クリック
「Next」クリック
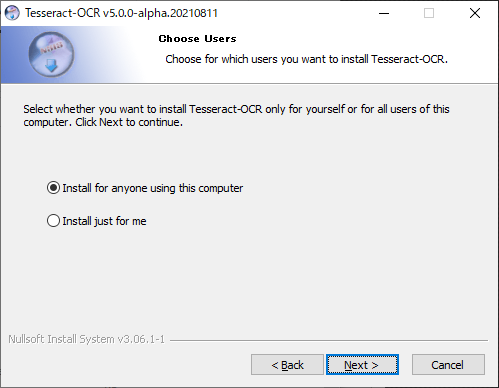
「Additional script data(download)」を展開
次の項目にチェック
- Japanese script
- Japanese vertical script
「Next」クリック
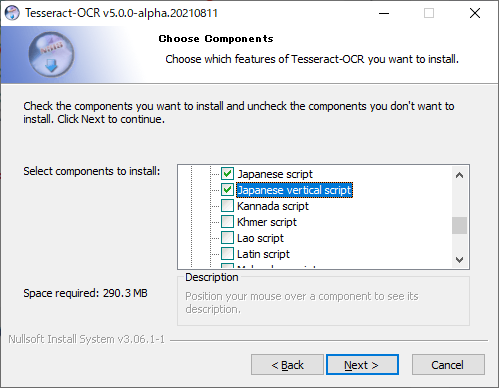
「Additional language data(download)」を展開
次の項目にチェック
- Japanese
- Japanese(Vertical)
「Next」クリック
その後は変更なしで進めていけば完了
サンプルソース
次の画像から文字列「Hello World!」を抽出してみましょ!
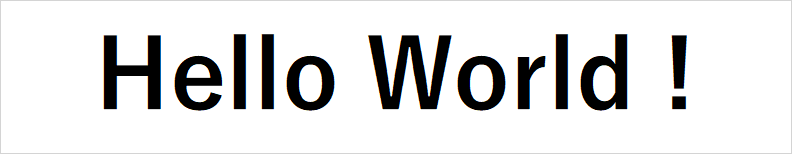
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from PIL import Image import sys import pyocr #tesseract.exeのパスを指定 pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe' #画像ファイルパス imgPath = 'hello.png' #OCRツールの呼び出し tools = pyocr.get_available_tools() if len(tools) == 0: print("OCRツールが見つかりませんでした") sys.exit(1) tool = tools[0] #画像から文字を抽出 txt = tool.image_to_string(Image.open(imgPath), lang="jpn") #空白を除去 txt = txt.replace(' ', '') #文字出力 print(txt) |
実行結果
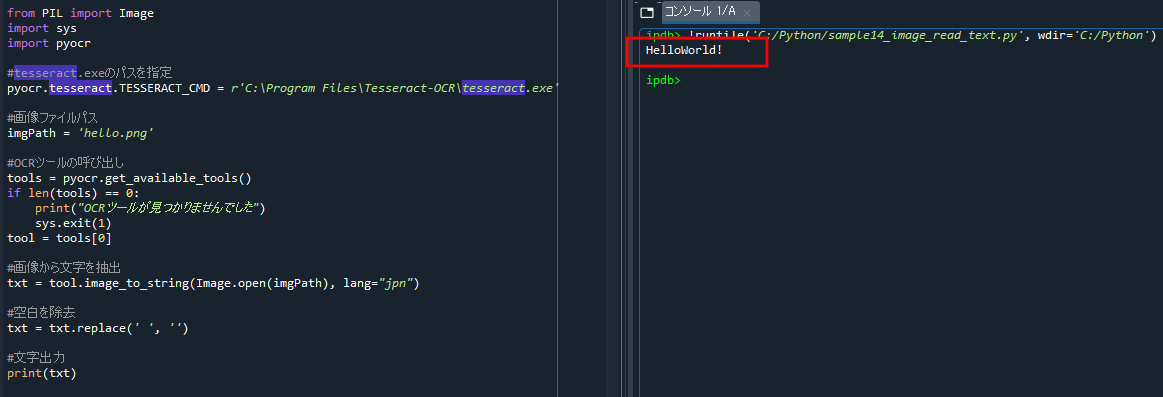


コメント